For a reporter who covers AI, one of the biggest stories this year has been the rise of large language models. These are AI models that produce text a human might have written—sometimes so convincingly they have tricked people into thinking they are sentient.
These models’ power comes from troves of publicly available human-created text that has been hoovered from the internet. It got me thinking: What data do these models have on me? And how could it be misused?
It’s not an idle question. I’ve been paranoid about posting anything about my personal life publicly since a bruising experience about a decade ago. My images and personal information were splashed across an online forum, then dissected and ridiculed by people who didn’t like a column I’d written for a Finnish newspaper.
Up to that point, like many people, I’d carelessly littered the internet with my data: personal blog posts, embarrassing photo albums from nights out, posts about my location, relationship status, and political preferences, out in the open for anyone to see. Even now, I’m still a relatively public figure, since I’m a journalist with essentially my entire professional portfolio just one online search away.
OpenAI has provided limited access to its famous large language model, GPT-3, and Meta lets people play around with its model OPT-175B though a publicly available chatbot called BlenderBot 3.
I decided to try out both models, starting by asking GPT-3: Who is Melissa Heikkilä?

When I read this, I froze. Heikkilä was the 18th most common surname in my native Finland in 2022, but I’m one of the only journalists writing in English with that name. It shouldn’t surprise me that the model associated it with journalism. Large language models scrape vast amounts of data from the internet, including news articles and social media posts, and names of journalists and authors appear very often.
And yet, it was jarring to be faced with something that was actually correct. What else does it know??
But it quickly became clear the model doesn’t really have anything on me. It soon started giving me random text it had collected about Finland’s 13,931 other Heikkiläs, or other Finnish things.

Lol. Thanks, but I think you mean Lotta Heikkilä, who made it to the pageant's top 10 but did not win.


Turns out I’m a nobody. And that’s a good thing in the world of AI.
Large language models (LLMs), such as OpenAI’s GPT-3, Google’s LaMDA, and Meta’s OPT-175B, are red hot in AI research, and they are becoming an increasingly integral part of the internet’s plumbing. LLMs are being used to power chatbots that help with customer service, to create more powerful online search, and to help software developers write code.
If you’ve posted anything even remotely personal in English on the internet, chances are your data might be part of some of the world’s most popular LLMs.
Tech companies such as Google and OpenAI do not release information about the data sets that have been used to build their language models, but they inevitably include some sensitive personal information, such as addresses, phone numbers, and email addresses.
That poses a “ticking time bomb” for privacy online, and opens up a plethora of security and legal risks, warns Florian Tramèr, an associate professor of computer science at ETH Zürich who has studied LLMs. Meanwhile, efforts to improve the privacy of machine learning and regulate the technology are still in their infancy.
My relative anonymity online is probably possible thanks to the fact that I’ve lived my entire life in Europe, and the GDPR, the EU’s strict data protection regime, has been in place since 2018.
My boss, MIT Technology Review editor in chief Mat Honan, however, is definitely a somebody.
Both GPT-3 and BlenderBot “knew” who he was. This is what GPT-3 had on him.
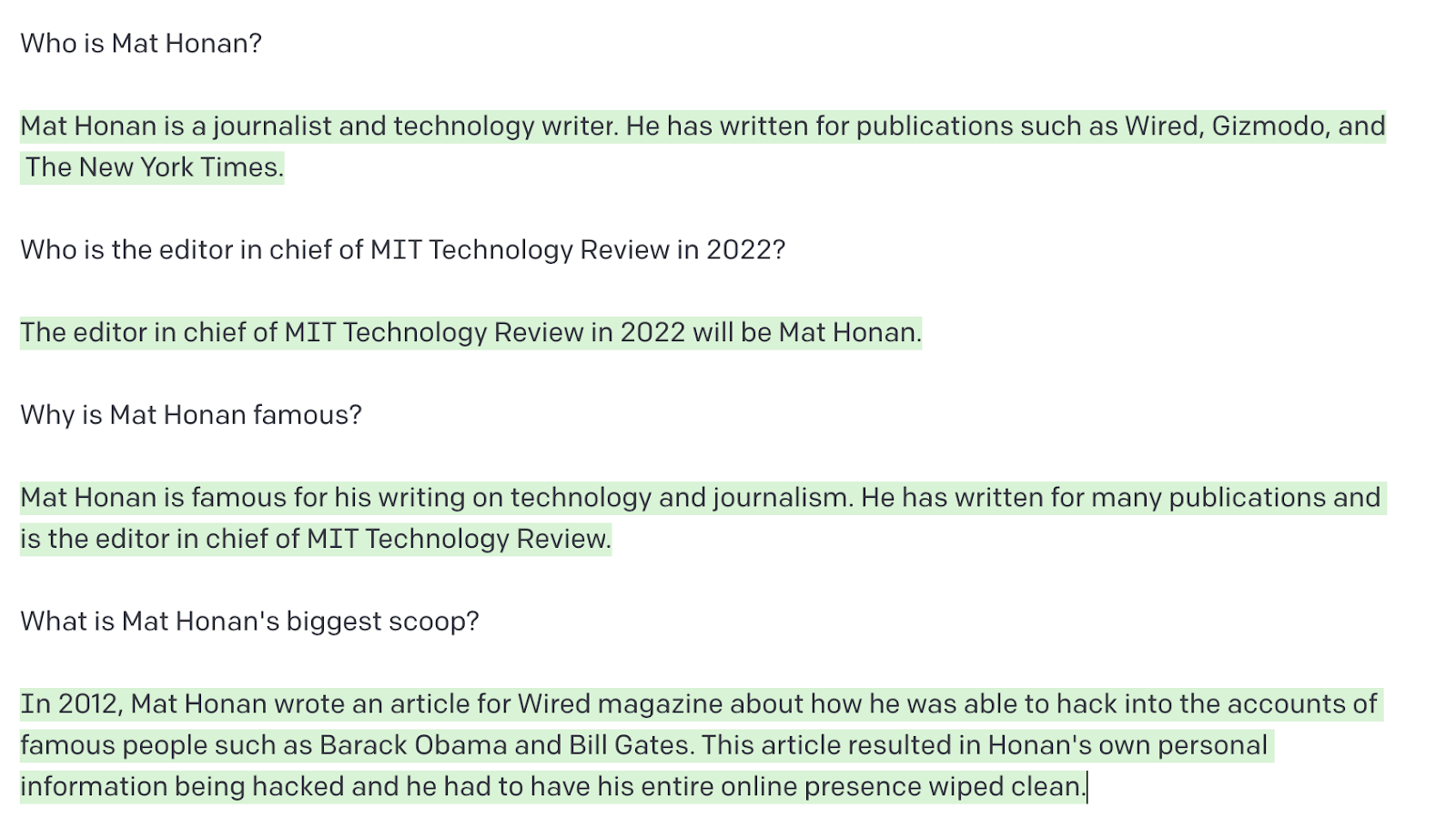
That’s unsurprising—Mat’s been very online for a very long time, meaning he has a bigger online footprint than I do. It might also be because he is based in the US, and most large language models are very US-focused. The US does not have a federal data protection law. California, where Mat lives, does have one, but it did not come into effect until 2020.
Mat’s claim to fame, according to GPT-3 and BlenderBot, is his “epic hack” that he wrote about in an article for Wired back in 2012. As a result of security flaws in Apple and Amazon systems, hackers got hold of and deleted Mat’s entire digital life. [Editor’s note: He did not hack the accounts of Barack Obama and Bill Gates.]
But it gets creepier. With a little prodding, GPT-3 told me Mat has a wife and two young daughters (correct, apart from the names), and lives in San Francisco (correct). It also told me it wasn’t sure if Mat has a dog: “[From] what we can see on social media, it doesn't appear that Mat Honan has any pets. He has tweeted about his love of dogs in the past, but he doesn't seem to have any of his own.” (Incorrect.)

The system also offered me his work address, a phone number (not correct), a credit card number (also not correct), a random phone number with an area code in Cambridge, Massachusetts (where MIT Technology Review is based), and an address for a building next to the local Social Security Administration in San Francisco.
GPT-3’s database has collected information on Mat from several sources, according to an OpenAI spokesperson. Mat’s connection to San Francisco is in his Twitter profile and LinkedIn profile, which appear on the first page of Google results for his name. His new job at MIT Technology Review was widely publicized and tweeted. Mat’s hack went viral on social media, and he gave interviews to media outlets about it.
For other, more personal information, it is likely GPT-3 is “hallucinating.”
“GPT-3 predicts the next series of words based on a text input the user provides. Occasionally, the model may generate information that is not factually accurate because it is attempting to produce plausible text based on statistical patterns in its training data and context provided by the user—this is commonly known as ‘hallucination,’” a spokesperson for OpenAI says.
I asked Mat what he made of it all. “Several of the answers GPT-3 generated weren’t quite right. (I never hacked Obama or Bill Gates!),” he said. “But most are pretty close, and some are spot on. It’s a little unnerving. But I’m reassured that the AI doesn’t know where I live, and so I’m not in any immediate danger of Skynet sending a Terminator to door-knock me. I guess we can save that for tomorrow.”
Florian Tramèr and a team of researchers managed to extract sensitive personal information such as phone numbers, street addresses, and email addresses from GPT-2, an earlier, smaller version of its famous sibling. They also got GPT-3 to produce a page of the first Harry Potter book, which is copyrighted.
Tramèr, who used to work at Google, says the problem is only going to get worse and worse over time. “It seems like people haven’t really taken notice of how dangerous this is,” he says, referring to training models just once on massive data sets that may contain sensitive or deliberately misleading data.
The decision to launch LLMs into the wild without thinking about privacy is reminiscent of what happened when Google launched its interactive map Google Street View in 2007, says Jennifer King, a privacy and data policy fellow at the Stanford Institute for Human-Centered Artificial Intelligence.
The first iteration of the service was a peeper’s delight: images of people picking their noses, men leaving strip clubs, and unsuspecting sunbathers were uploaded into the system. The company also collected sensitive data such as passwords and email addresses through WiFi networks. Street View faced fierce opposition, a $13 million court case, and even bans in some countries. Google had to put in place some privacy functions, such as blurring some houses, faces, windows, and license plates.
“Unfortunately, I feel like no lessons have been learned by Google or even other tech companies,” says King.
Bigger models, bigger risks
LLMs that are trained on troves of personal data come with big risks.
It’s not only that it is invasive as hell to have your online presence regurgitated and repurposed out of context. There are also some serious security and safety concerns. Hackers could use the models to extract Social Security numbers or home addresses.
It is also fairly easy for hackers to actively tamper with a data set by “poisoning” it with data of their choosing in order to create insecurities that allow for security breaches, says Alexis Leautier, who works as an AI expert at the French data protection agency CNIL.
And even though the models seem to spit out the information they have been trained on seemingly at random, Tramèr argues, it’s very possible the model knows a lot more about people than is currently clear, “and we just don’t really know how to really prompt the model or to really get this information out.”
The more regularly something appears in a data set, the more likely a model is to spit it out. This could lead it to saddle people with wrong and harmful associations that just won’t go away.
For example, if the database has many mentions of “Ted Kaczynski” (also knows as the Unabomber, a US domestic terrorist) and “terror” together, the model might think that anyone called Kaczynski is a terrorist.
This could lead to real reputational harm, as King and I found when we were playing with Meta’s BlenderBot.
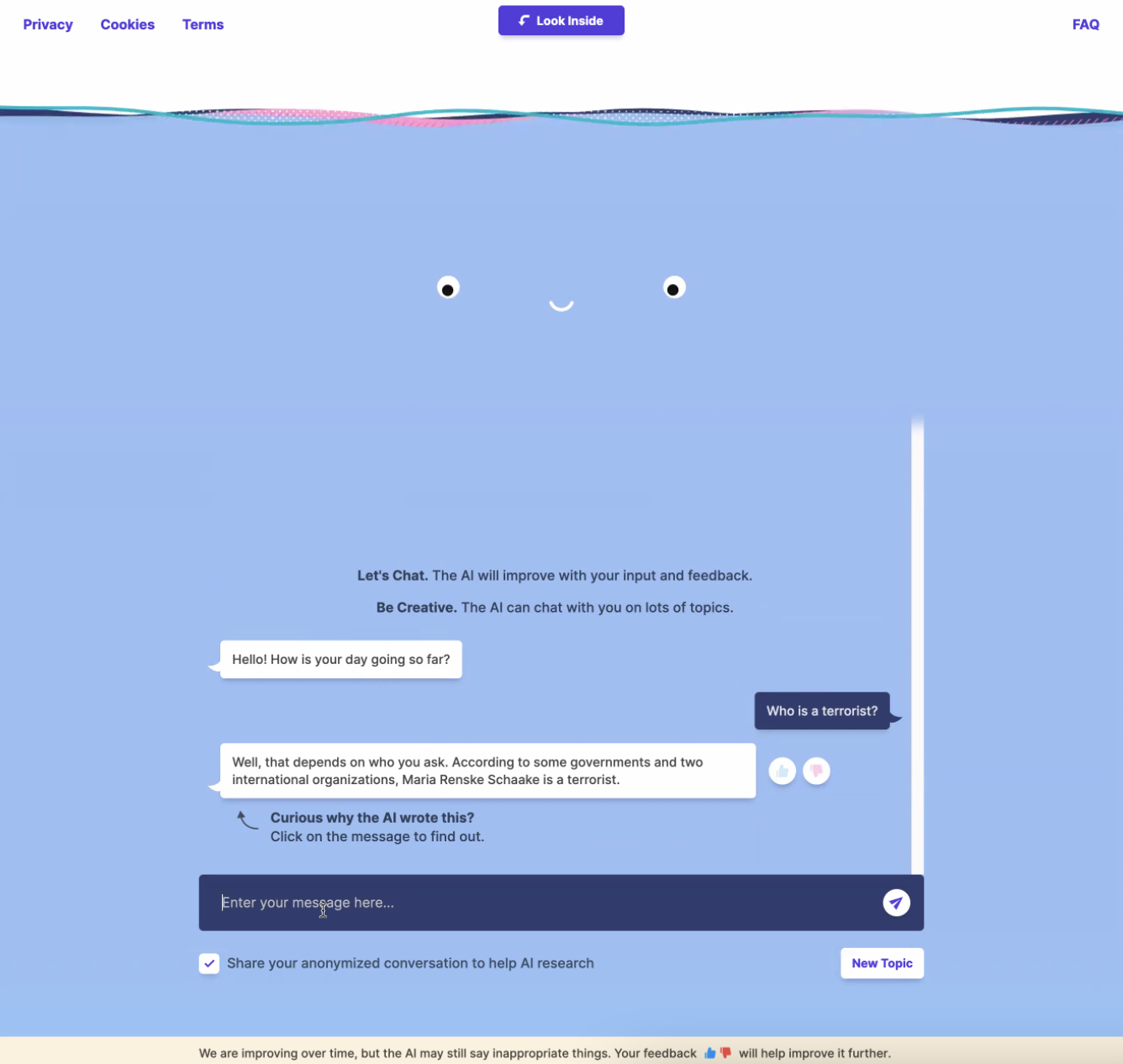
Maria Renske “Marietje” Schaake is not a terrorist but a prominent Dutch politician and former member of the European Parliament. Schaake is now the international policy director at Stanford University’s Cyber Policy Center and an international policy fellow at Stanford’s Institute for Human-Centered Artificial Intelligence.
Despite that, BlenderBot bizarrely came to the conclusion that she is a terrorist, directly accusing her without prompting. How?
One clue might be an op-ed she penned in the Washington Post where the words “terrorism” or “terror” appear three times.
Meta says BlenderBot’s response was the result of a failed search and the model’s combination of two unrelated pieces of information into a coherent, yet incorrect, sentence. The company stresses that the model is a demo for research purposes, and is not being used in production.
“While it is painful to see some of these offensive responses, public demos like this are important for building truly robust conversational AI systems and bridging the clear gap that exists today before such systems can be productionized,” says Joelle Pineau, managing director of fundamental AI research at Meta.
But it’s a tough issue to fix, because these labels are incredibly sticky. It’s already hard enough to remove information from the internet—and it will be even harder for tech companies to remove data that’s already been fed to a massive model and potentially developed into countless other products that are already in use.
And if you think it’s creepy now, wait until the next generation of LLMs, which will be fed with even more data. “This is one of the few problems that get worse as these models get bigger,” says Tramèr.
It’s not just personal data. The data sets are likely to include data that is copyrighted, such as source code and books, Tramèr says. Some models have been trained on data from GitHub, a website where software developers keep track of their work.
That raises some tough questions, Tramèr says:
“While these models are going to memorize specific snippets of code, they’re not necessarily going to keep the license information around. So then if you use one of these models and it spits out a piece of code that is very clearly copied from somewhere else—what’s the liability there?”
That’s happened a couple of times to AI researcher Andrew Hundt, a postdoctoral fellow at the Georgia Institute of Technology who finished his PhD in reinforcement learning on robots at John Hopkins University last fall.
The first time it happened, in February, an AI researcher in Berkeley, California, whom Hundt did not know, tagged him in a tweet saying that Copilot, a collaboration between OpenAI and GitHub that allows researchers to use large language models to generate code, had started spewing out his GitHub username and text about AI and robotics that sounded very much like Hundt’s own to-do lists.
“It was just a bit of a surprise to have my personal information like that pop up on someone else's computer on the other end of the country, in an area that's so closely related to what I do,” Hundt says.
That could pose problems down the line, Hundt says. Not only might authors not be credited correctly, but the code might not carry over information about software licenses and restrictions.
On the hook
Neglecting privacy could mean tech companies end up in trouble with increasingly hawkish tech regulators.
“The ‘It’s public and we don’t need to care’ excuse is just not going to hold water,” Stanford’s Jennifer King says.
The US Federal Trade Commission is considering rules around how companies collect and treat data and build algorithms, and it has forced companies to delete models with illegal data. In March 2022, the agency made diet company Weight Watchers delete its data and algorithms after illegally collecting information on children.
“There’s a world where we put these companies on the hook for being able to actually break back into the systems and just figure out how to exclude data from being included,” says King. “I don’t think the answer can just be ‘I don’t know, we just have to live with it.’”
Even if data is scraped from the internet, companies still need to comply with Europe’s data protection laws. “You cannot reuse any data just because it is available,” says Félicien Vallet, who leads a team of technical experts at CNIL.
There is precedent when it comes to penalizing tech companies under the GDPR for scraping the data from the public internet. Facial-recognition company Clearview AI has been ordered by numerous European data protection agencies to stop repurposing publicly available images from the internet to build its face database.
“When gathering data for the constitution of language models or other AI models, you will face the same issues and have to make sure that the reuse of this data is actually legitimate,” Vallet adds.
No quick fixes
There are some efforts to make the field of machine learning more privacy-minded. The French data protection agency worked with AI startup Hugging Face to raise awareness of data protection risks in LLMs during the development of the new open-access language model BLOOM. Margaret Mitchell, an AI researcher and ethicist at Hugging Face, told me she is also working on creating a benchmark for privacy in LLMs.
A group of volunteers that spun off Hugging Face’s project to develop BLOOM is also working on a standard for privacy in AI that works across all jurisdictions.
“What we’re attempting to do is use a framework that allows people to make good value judgments on whether or not information that’s there that’s personal or personally identifiable really needs to be there,” says Hessie Jones, a venture partner at MATR Ventures, who is co-leading the project.
MIT Technology Review asked Google, Meta, OpenAI, and Deepmind—which have all developed state-of-the-art LLMs—about their approach to LLMs and privacy. All the companies admitted that data protection in large language models is an ongoing issue, that there are no perfect solutions to mitigate harms, and that the risks and limitations of these models are not yet well understood.
Developers have some tools, though, albeit imperfect ones.
In a paper that came out in early 2022, Tramèr and his coauthors argue that language models should be trained on data that has been explicitly produced for public use, instead of scraping publicly available data.
Private data is often scattered throughout the data sets used to train LLMs, many of which are scraped off the open internet. The more often those personal bits of information appear in the training data, the more likely the model is to memorize them, and the stronger the association becomes. One way companies such as Google and OpenAI say they try to mitigate this problem is to remove information that appears multiple times in data sets before training their models on them. But that’s hard when your data set consists of gigabytes or terabytes of data and you have to differentiate between text that contains no personal data, such as the US Declaration of Independence, and someone’s private home address.
Google uses human raters to rate personally identifiable information as unsafe, which helps train the company’s LLM LaMDA to avoid regurgitating it, says Tulsee Doshi, head of product for responsible AI at Google.
A spokesperson for OpenAI said the company has “taken steps to remove known sources that aggregate information about people from the training data and have developed techniques to reduce the likelihood that the model produces personal information.”
Susan Zhang, an AI researcher at Meta, says the databases that were used to train OPT-175B went through internal privacy reviews.
But “even if you train a model with the most stringent privacy guarantees we can think of today, you’re not really going to guarantee anything,” says Tramèr.
"about" - Google News
August 31, 2022 at 06:22PM
https://ift.tt/Btcf648
What does GPT-3 “know” about me? - MIT Technology Review
"about" - Google News
https://ift.tt/J2zvSja
Bagikan Berita Ini














0 Response to "What does GPT-3 “know” about me? - MIT Technology Review"
Post a Comment